
We're releasing today, in research preview, a new way to program machines - using natural language. Our first-generation program synthesis engine, PAC-1, takes in steps written in English, assembles a discrete program graph, and deploys ready-to-use software on our compute infrastructure. This makes it possible to spin up machine workers on demand to perform multi-step tasks (Fig 1) in a few lines of code, using our API:
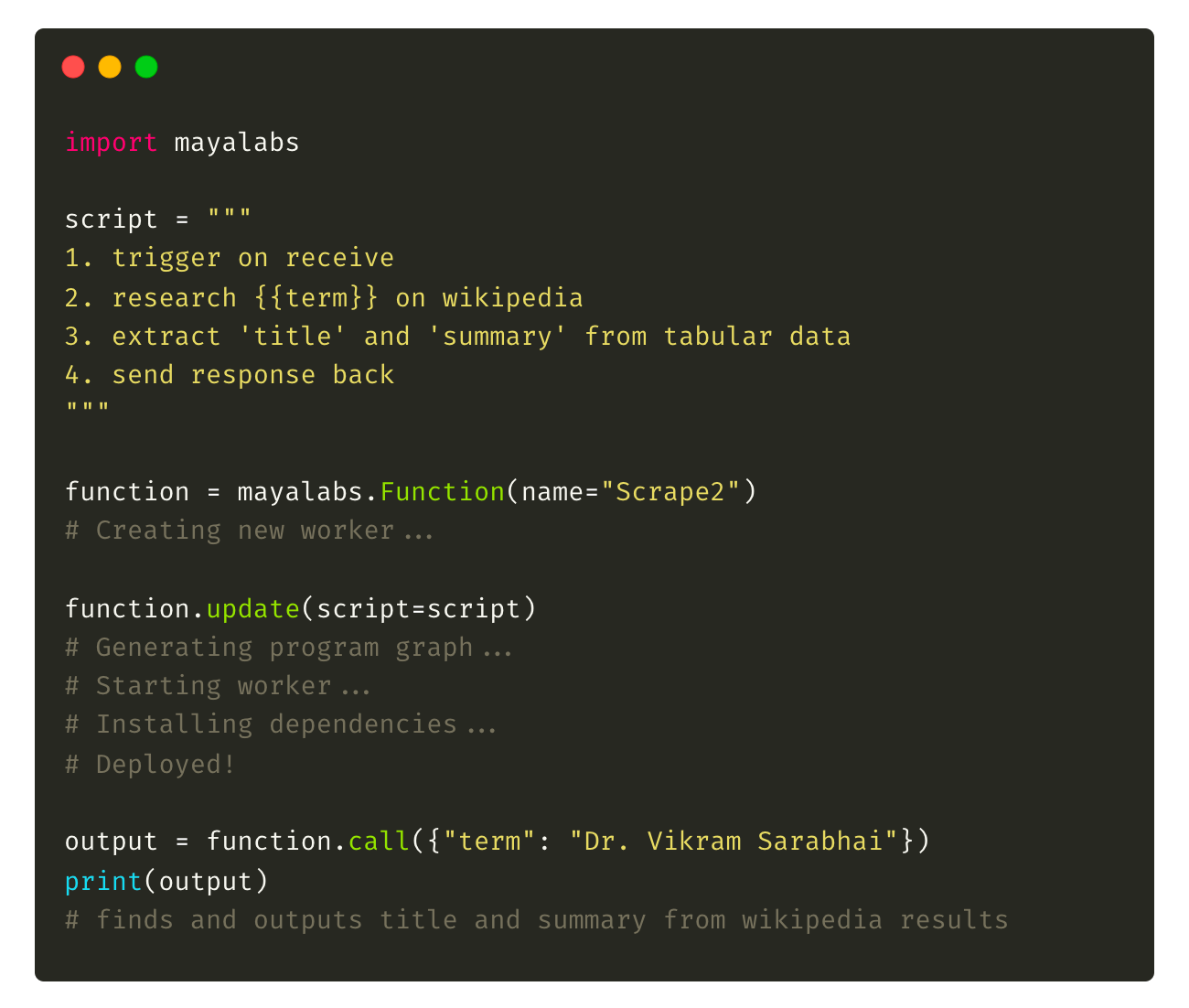
Full list of capabilities and limitations here.
Plasticity
Recent advances in generative models for text, image and code have opened up new ways for machines to do more with less. However, unlike biological learners that continuously learn from and adapt to uncertainty, these systems are rigid, inscrutable and fixed in time, requiring large amounts of data and compute to update themselves and learn anything new.
A few years ago, we embarked on a different research approach - to build interpretable AI systems that demonstrate plasticity - or the ability to flexibly learn, retain & modify behaviour from a few demonstrations. To test some of these ideas in practice, we're opening up the Maya platform for general use, which includes a Python SDK, CLI and a command bar to summon it from within the browser, along with a visual flow-based IDE to easily edit and interpret the execution of the programs it generates :


At the heart of PAC-1 (standing for Plastic Auto-Constructor, reflecting the flexible, abstract construction of interpretable concept libraries) is our natural language interpreter that converts the symbols in which humans think - natural language - to symbols in which machines think - programs.
It brings to real-world tasks the learnings from Flatland, a toy environment, DSL & benchmark we built in early 2022, for synthesising functional programs to draw 2D line images. Progress on Flatland draws from recent breakthroughs in neuro-symbolic AI systems , which have resulted in powerful reasoning for visual[1], spatial[2], action[3], and theoretical[4], gameplay[5] understanding, approximating functions from just a few samples.

These unlock a few important benefits, in both directing and interpreting machine behaviour :
- Interpretability: Machine-generated text and art allow for creative output and can be quickly checked for accuracy, but code requires precision and debugging skills. Providing a high-level list of steps in plain English allows anyone to read and understand the code before and after deployment. The program itself is a description of its behaviour.
- Composability: Condensing complex behaviour into a brief list of steps makes it possible to hold and move around the natural language program in one's head. This enables easier planning and task breakdown for both humans and machines, making complex tasks more tractable.
- Portability : Compressing software to a list of steps in English makes it easy to package and move it around, copy-pasting it to others over a text message, storing it in a note taking app, viewing it in a terminal, in a chatbot response, or version controlling it in a repository.

Once a sketch is approximated, the PAC-1 interpreter assembles a flow-based program using open-source reusable blocks for each step, and deploys it on a unit of ephemeral compute on our servers called a Worker. The frontend, backend, API calls, are all stitched into one large functional graph, that behaves like data-processing factory - networks of reusable components running "black-box" functions, which communicate via data chunks travelling across defined connections (Figure 6).
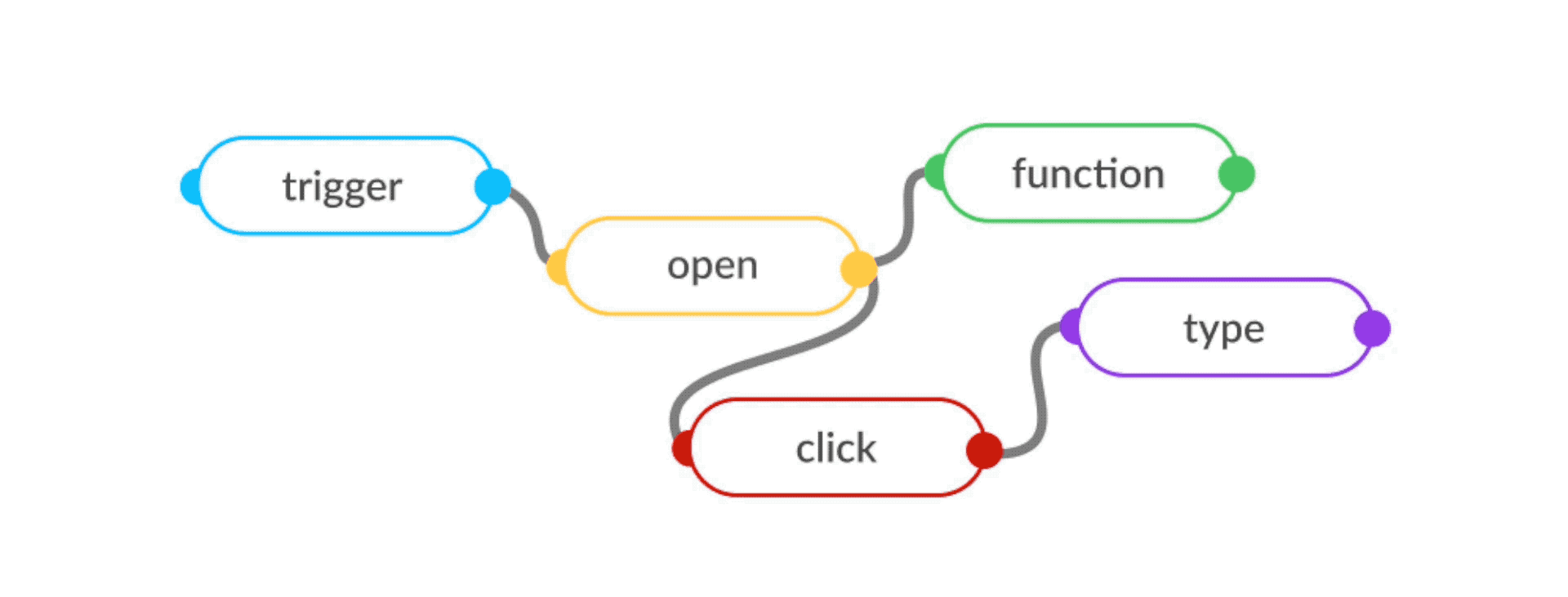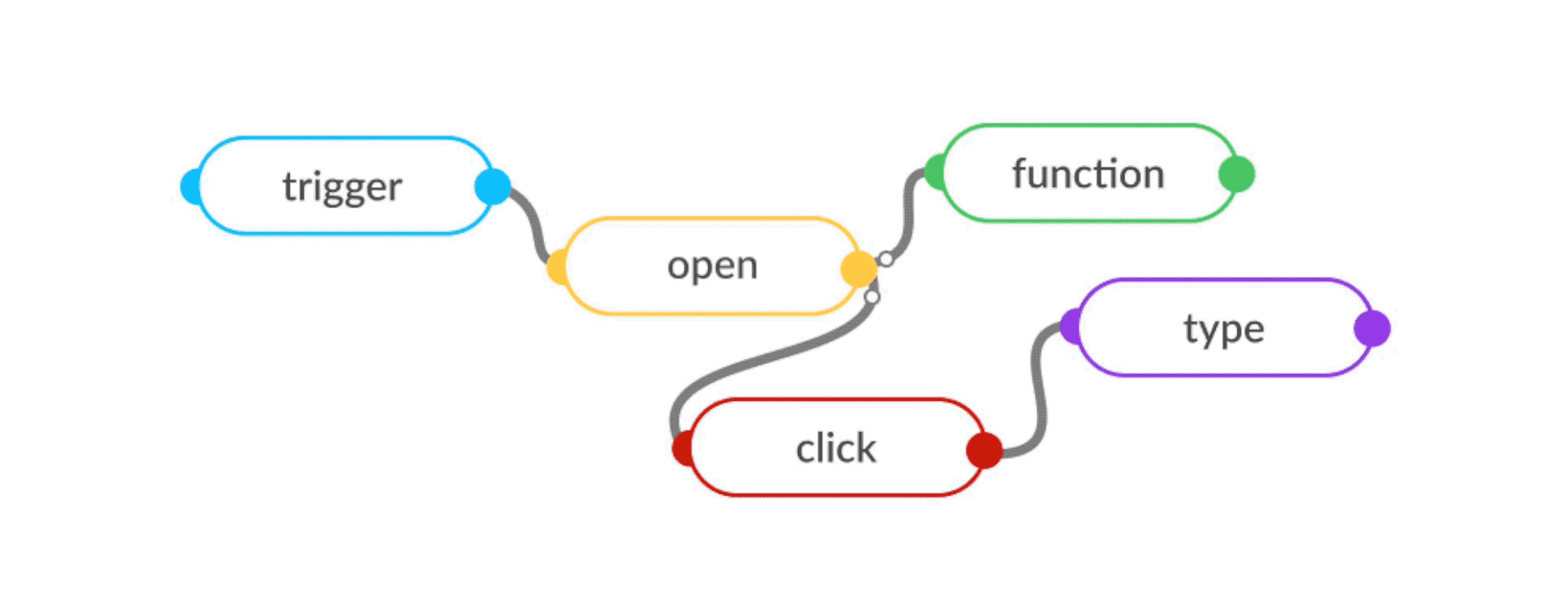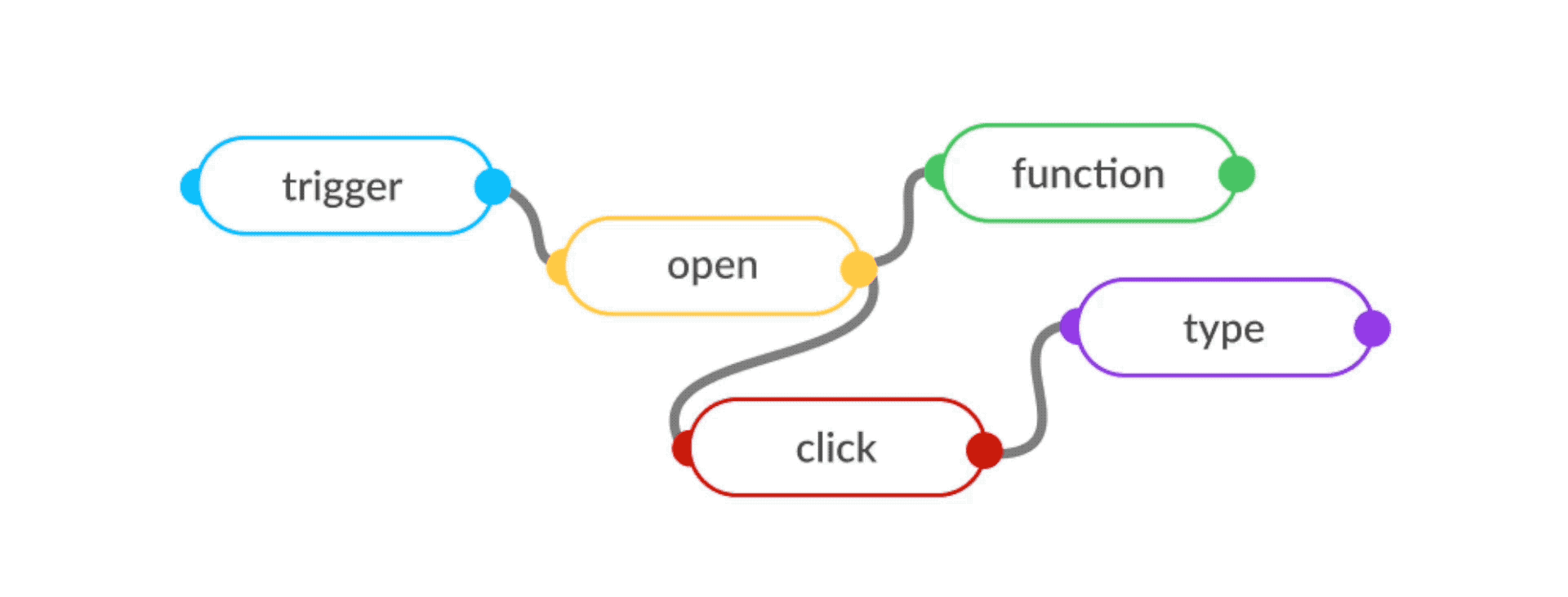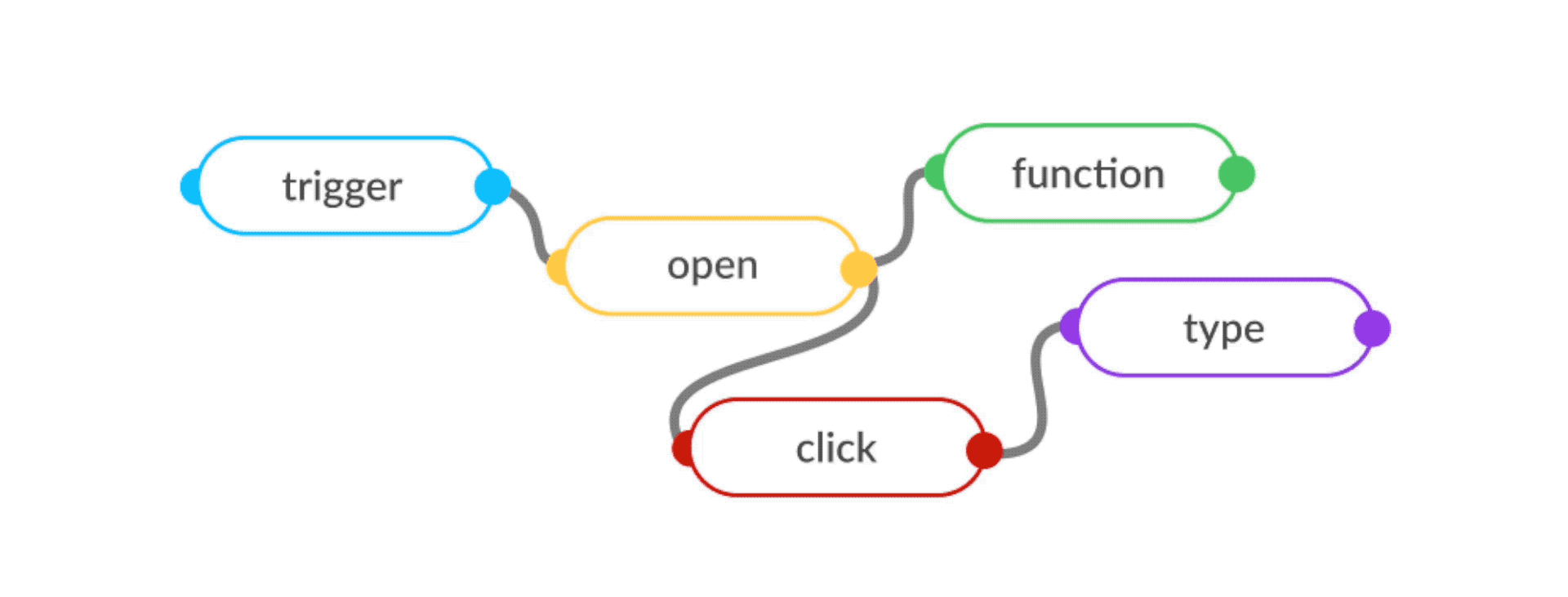
Post-deployment, in response to instructions, PAC-1 modifies its behaviour by detecting and regenerating only the changed steps, and deploying only the incremental changes - shortening the feedback loop between command, generated software and executed output to seconds.
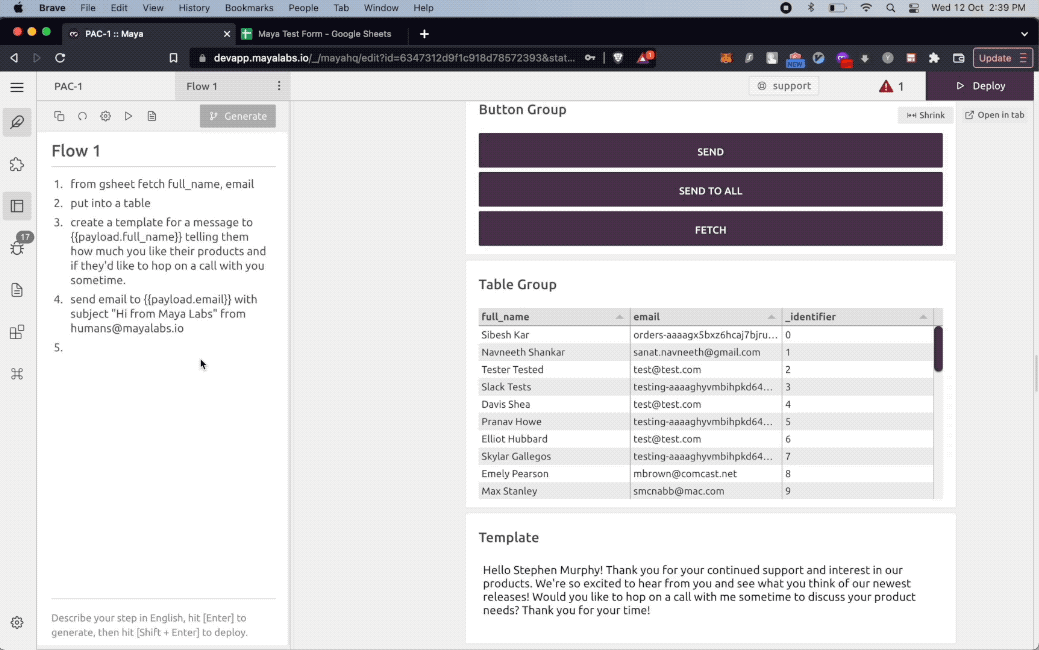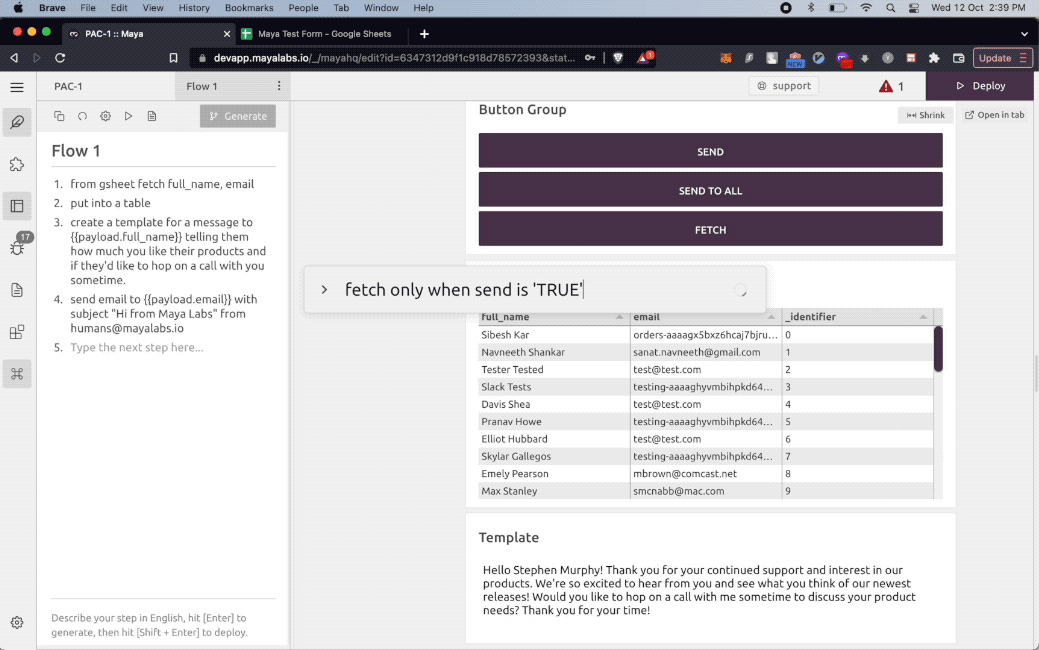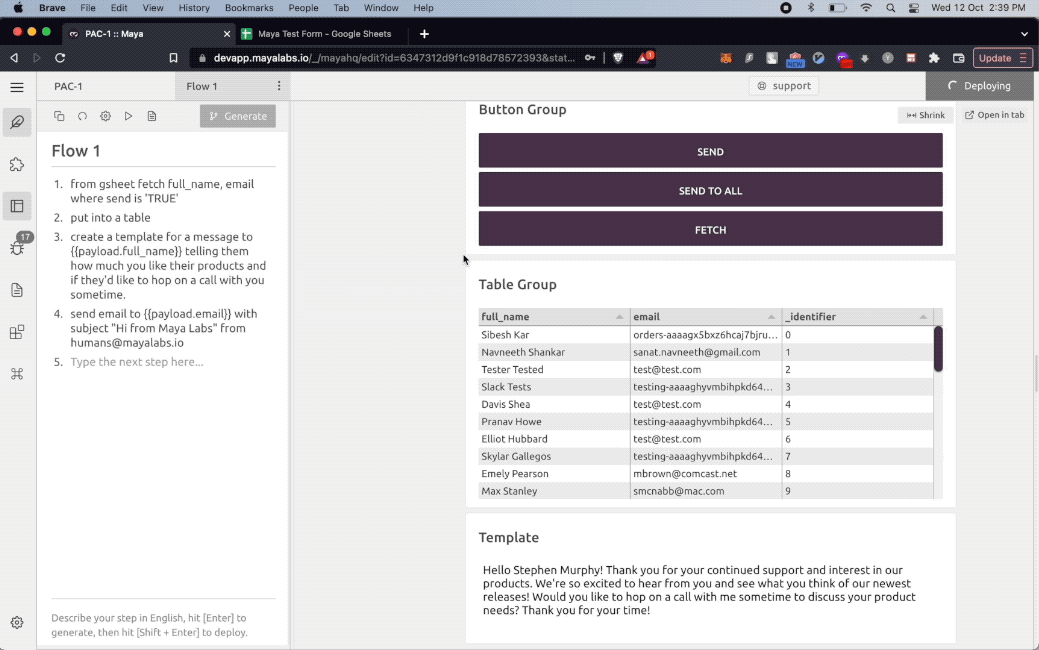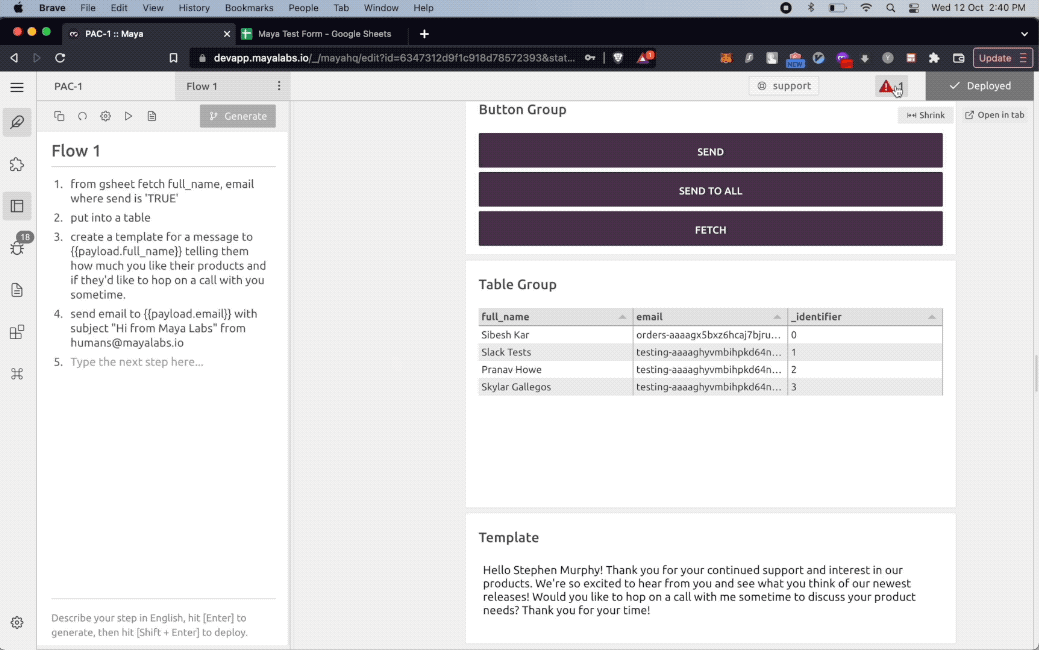
Use Cases
The PAC-1 natural language interpreter can assemble natural language programs across a wide range of useful tasks and applications. It comes equipped with a standard library of functions that can be indefinitely extended and built on top of. Here are a few examples :
If...Then Conditionals and Looping
A simple if...then else switch, with a loop written in English.
1. set {{payload}} to 0
2. add 1 to {{payload}}
3. print {{payload}}
4. if {{payload}} is less than 20
- 4.1. go to step 2
5. else if {{payload}} is more than 20
- 4.2. print {{payload}}Custom Functions
PAC-1 uses code generation models for synthesising custom functions for simple variable manipulation.
1. trigger on recieve
2. make a GET request to '<apilink>'
3. run a custom function to 'add 5 to every element of {{payload}}'
4. send response backWeb Scrapers
Fetching data from a source, and splitting it into three branches that go scrape the web, and display results in a table.
1. from gsheet get {{Name}}, {{Website}}, {{Company}}, {{Email}}, {{Linkedin}}
2. split data into batches and send at intervals of 2 seconds
- 2.1. scrape and extract title, description and text from {{Website}}
2.1.1. go to step 3
- 2.2. scrape and extract text from {{Linkedin}}
2.2.1. go to step 3
- 2.3. store {{Company}} in {{company}}
2.3.1. go to step 3
3. show in a table with button ResearchRepeating Workflows
We have here a script that has been designed to run manually.
1. inject default
2. fetch weekly mongo records for collection synth-db
3. save to s3 bucket 'synth-db-backup'It can be made to repeat at arbitrary intervals, by inserting just one step in the beginning.
1. repeat every 5 days, starting Monday
2. fetch weekly mongo records for collection synth-db
3. save to s3 bucket 'synth-db-backup'This makes cron-like scheduling possible for any set of steps.
Custom Dashboards
Modelling interactive UI components like tables, rich-text, forms, buttons, templates, images, which can be used in the beginning of a script:
// create a form to put data into spreadsheet
1. create a form with fields {{Name}}, {{Age}}, {{Occupation}}
2. put Name, Age, Occupation into gsheetOr interspersed in between steps.
// create a dashboard to ask questions about an SQL db
// and
1. add a button with label 'fetch schema'
- 1.1. connect to a MySQL Database and store it's create schema in {{schema}}
1.2. store {{schema}} in flow.{{context}}
2. show a text editor to take input {{input}}
3. create sql query to get {{input}} using {{schema}}
4. show a text editor to show {{query}}
5. run sql query {{query}} on MySQL
6. show results in table with button 'Submit'Data Transformation
Moving data from one data source to another, and modifying in between by just adding a few display steps.
For instance, here's a natural language script to move some columns from SQL to Gsheet.
1. from SQL fetch 'all users who live in Bangalore'
2. put all data into gsheetWhich can be changed into an interactive dashboard by adding three lines in between, for showing the data in a table and modifying it item-wise in a form.
1. from SQL fetch 'all users who live in Bangalore'
2. show in a table with button labelled Modify
- 2.1. edit in a form with fields User, Name, Email
2.1. go to step 3
3. put all data into gsheetPlatform Bots
A Reddit bot that filters and sends messages to a Slack bot.
//
1. search subreddit r/dankmemes for 'automation', order by top daily
2. filter out all messages that include ["BOTS", "AMA"]
2. send to channel #alerts on slackLong Business Processes
PAC-1 can be taught and interpret to scripts of arbitrary complexity and length, extending to complex business processes. For instance, the script below automates a sales process of fetching leads from a google sheet, researching them on the web, composing blurbs to place in the mails based on some email templates it's been shown before.
"""
1. from gsheet get {{Name}}, {{Website}}, {{Company}}, {{Email}}, {{Linkedin}}
2. split data into batches and send at intervals of 2 seconds
- 2.1. scrape and extract title, description and text from {{Website}}
2.1.1. go to step 3
- 2.2. scrape and extract text from {{Linkedin}}
2.2.1. go to step 3
- 2.3. store {{Company}} in {{company}}
2.3.1. go to step 3
3. show in a table with button Research
4. create a research prompt with instructions "Write a 100 word blurb on {{company}}"
- 4.1. show in text editor
4.2. go to step 5
5. generate using large model
- 5.1. show in text editor
5.2. go to step 5.2.1
5.2.1. set {{global.CompanyBlurb}} to {{msg.payload.completed}}, delete {{global.CompanyInfo}}, delete {{msg.payload.completed}}
5.2.2. go to step 5.2.3.
- 5.2.3. AI email template search in doc library
- 5.2.3.1. go to step 6
- 5.2.4. Search company info in doc library
5.2.4.1 check search query results
5.2.4.2. if {{condition}} is Bad
- 5.2.4.2.1. rephrase search query
5.2.4.2.2. Loop thrice before breaking
5.2.4.2.3 go to step 5.2.
5.2.4.3. else if {{condition}} is Good
- 5.2.4.3.1. go to step 6
6. combine messages
7. create an email prompt with blurb from {{CompanyBlurb}} and description from {{CompanyInfo}} to "Write an email for {{Company}} in {{FromCompany}}'s perspective"
- 7.1. show in text editor
7.2. generate using large model
7.3 go to step 8
8. show output in editor
"""This script above just researches and composes mails, but adding a 'send to {{email}} using Sendgrid/Mailgun" at the end, could then send out the composed emails as well.
Long-term memory
PAC-1 can generating programs to selectively call its own API - in this case it's own native vector database, allowing for long-term storage and retrieval of knowledge.
// A command to store any document in a persistent database for later recall.
1. store {{payload}} in native memory
// Commands to search and ask questions from the stored documents, like this:
1. search native memory for 'emailing templates'
2. ask native memory 'What was the last internal memo?"Persisting information and use it later across Workers and programs, like this :
// Worker 1
1. research 'Nelson Mandela' on wikipedia
2. store {{payload}} to native memory
// Worker 2
1. search native memory for 'Nelson Mandela monuments'
2. create a prompt to "write a 100 word essay about the monuments named after nelson mandela"
3. generate using a large language modelDivision of Labour
Since PAC-1 can call its own API, Maya Workers can requisition other workers, deploy custom software on them, and instruct each other to make changes.
For instance, take this simple task that fetches certain data from SQL every day and sends it to a slack channel :
// every day at 5pm, fetch all users who signed up today and send to channel #insights on slack
1. repeat every day at 5pm
2. connect to a MySQL Database and store it's create schema in {{schema}}
3. store {{schema}} in flow.{{context}}
4. create sql query to run 'fetch all users who signed up today' using {{schema}}
5. send to slack channel #insightsIf you wanted to try instantiate different variations of this task in one go in parallel, you could just teach PAC-1 a script to spawn new workers :
// fetch relevant user insights and send alerts to slack
1. add a button with label 'Spawn Workers'
- 1.1. spawn a worker 'ABC' to run 'fetch all the users who signed up and send to channel #growth on slack, every day at 8pm'
- 1.2. spawn a worker 'DEF' which runs 'fetch all the users who churned this week and send to channel #growth on slack, every week on Monday'
- 1.3. spawn a worker 'GHI' which runs 'fetch all users in the schema and send to channel #marketing on slack'Tasks can also be broken down and distributed concurrently amongst workers, so they function as an assembly line, like this script that splits the task of creating a report on the product sales every month :
1. add a button with label 'Create Workers'
- 1.1. spawn a worker 'ABC' to run "query SQL to fetch all products that sold more than 5000 units this month"
1.1.2. go to step 2
- 1.2. create worker 'DEF' to run 'create a PDF report based on the tabular data in {{rowData}}'
1.2.2. go to step 2
2. call worker 'ABC'
3. set {{rowData}} to {{payload}}
4. call worker 'DEF' with {{rowData}}
5. print {{payload}}
6. repeat every month, second Saturday
- 5.1. send instruction 'add 1000 to units value to be checked'
5.2. go to step 2Reducing the cost and time to automate a task by a few orders of magnitude opens up the ability to instantly create, deploy and dispose software to do new tasks at will. Ten slightly different variations of a task could be instantiated on command, with instant feedback from their results. The tasks that fail can be discarded with no sunken cost and those that work can then be scaled across many Maya workers with just a single instruction. Different working tools can be stitched together into a single script, and the combination can further be reused for higher level script.
Teaching PAC-1 New Skills
The PAC-1 interpreter has been taught how to take a few basic actions as a part of it's standard library, and more skills are available on the Maya store, but it's capabilities can be extended by showing it 2-3 demonstrations of new programs, from within the editor.
This sort of programming by demonstration allows the creation of a natural language functions that behave predictably while displaying local generalisation to unseen commands.

For instance, if we teach it two similar flow programs to get data from a spreadsheet, one to :
get fields Name, Email, CompanyName from google sheet and a second one to :
from gsheet fetch Organization, first_name, email_addressPAC-1 understands the semantic differences, and predictably generalises to any unseen command of the form "get {{Field1}}, {{Field2}}, {{FieldN}} from google sheet", like:
fetch location, serial_id from google sheetsThis sort of flexible few-shot teaching means that if it generates the wrong program for an unusual command, like "get all data from gsheet" , it is possible to fix and update it's understanding of the task by providing just one extra correct example.

Towards General Abstraction and Reasoning
This new way of programming a machine in natural language means we can treat natural language as a functional LISP-like symbolic language, allowing for causal modelling of concepts in hierarchies, like a software parse tree. Instructions given at a high-level can trickle down to lower levels, allowing for granular control and coordination with fleets of machine 'workers' collaborating together at each level - in parallel, or as an assembly line. We can now view the 'learning process' as abstraction via repeated compression, and 'inference' as reasoning via repeated expansion, as shown in Fig 10 (below).
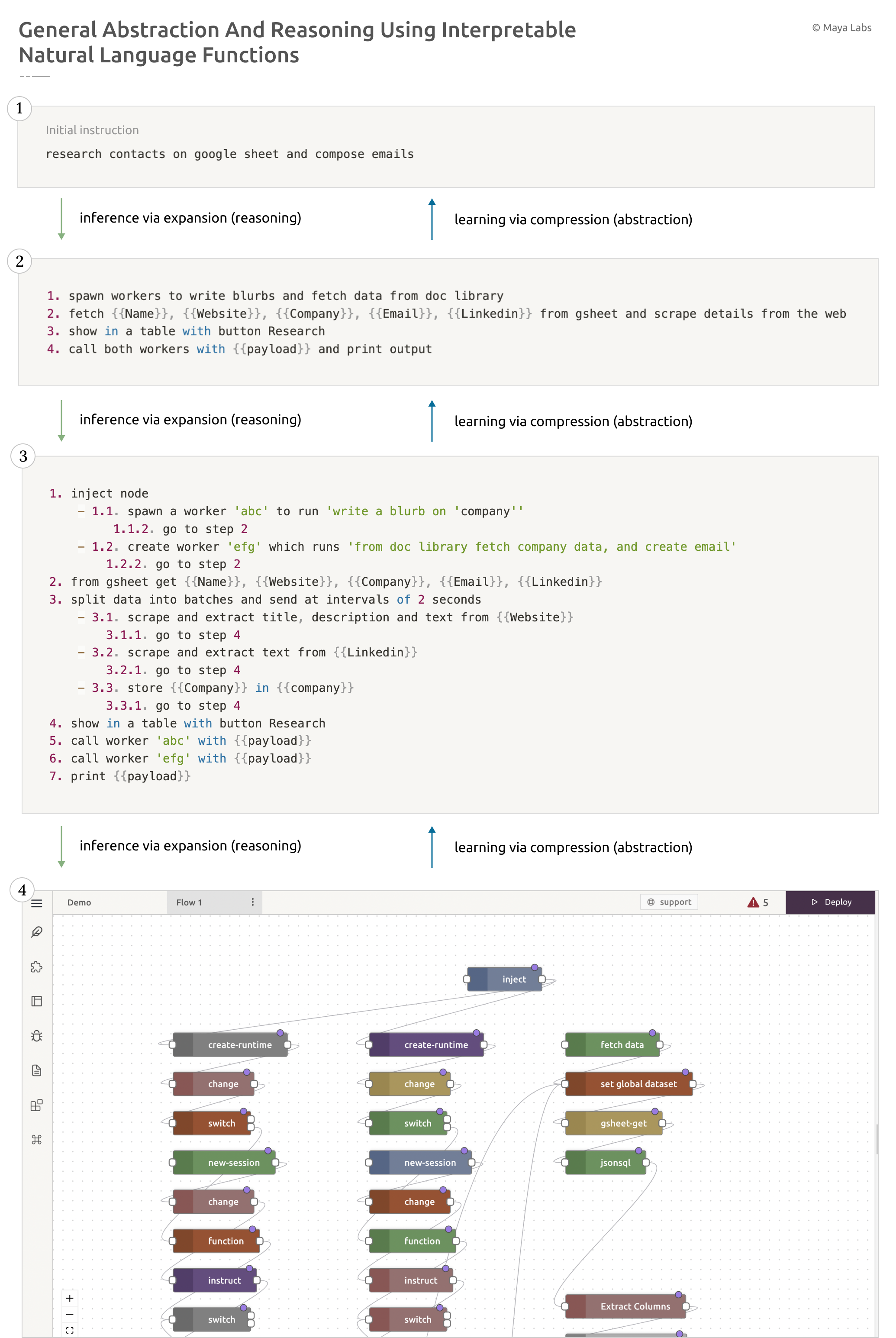
Looking Forward
We've designed PAC-1 to be a step towards fleets of versatile remote machine workers in the cloud that can be summoned, trained, and directed using natural language to write and run software, as easily as calling an API to provision a server on the cloud. Future versions could multiply human effort by making it possible to spin up entire organizational hierarchies in minutes that coordinate in interpretable ways to complete a task.
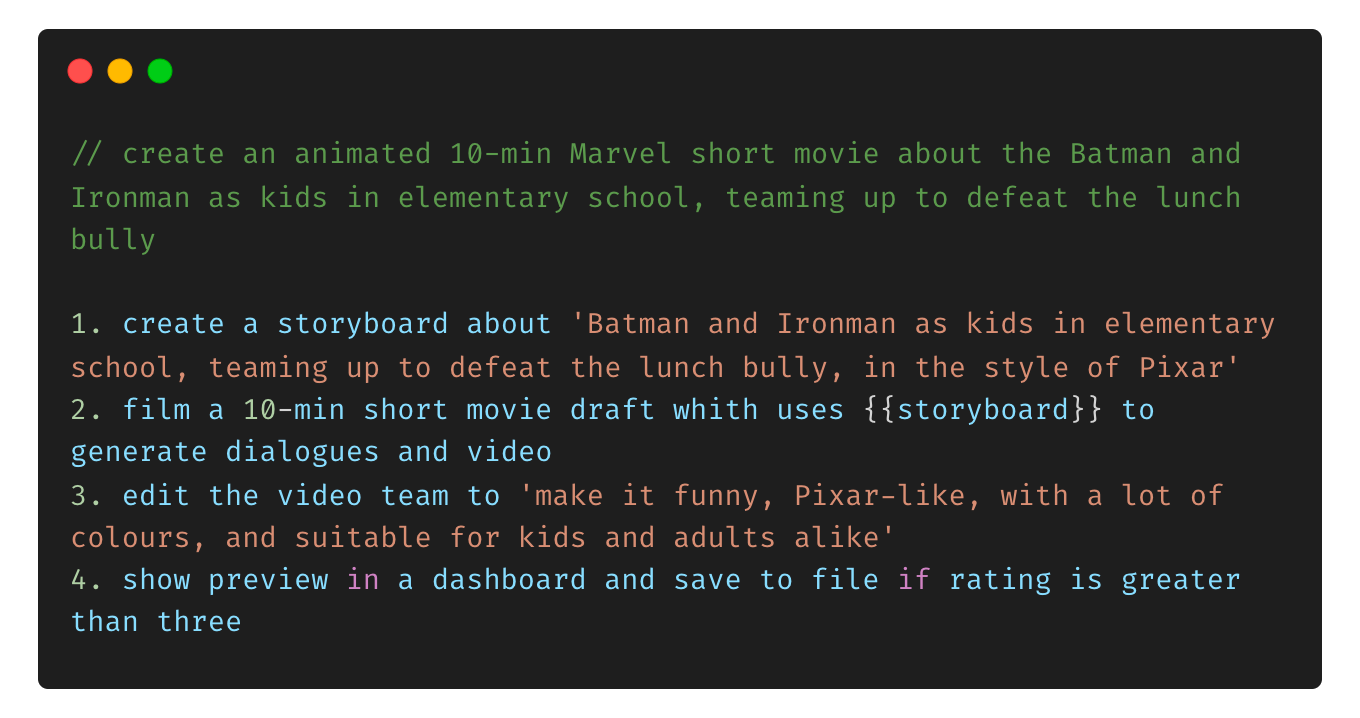
For instance, it could be possible to teach PAC how to perform any complex, multi-step process, like planning & creating a short film :

Which could expand to dividing the task into teams to handle each stage of movie-making:
Which could then expand to inducing a program for what each modular team does, before passing it on to the next :
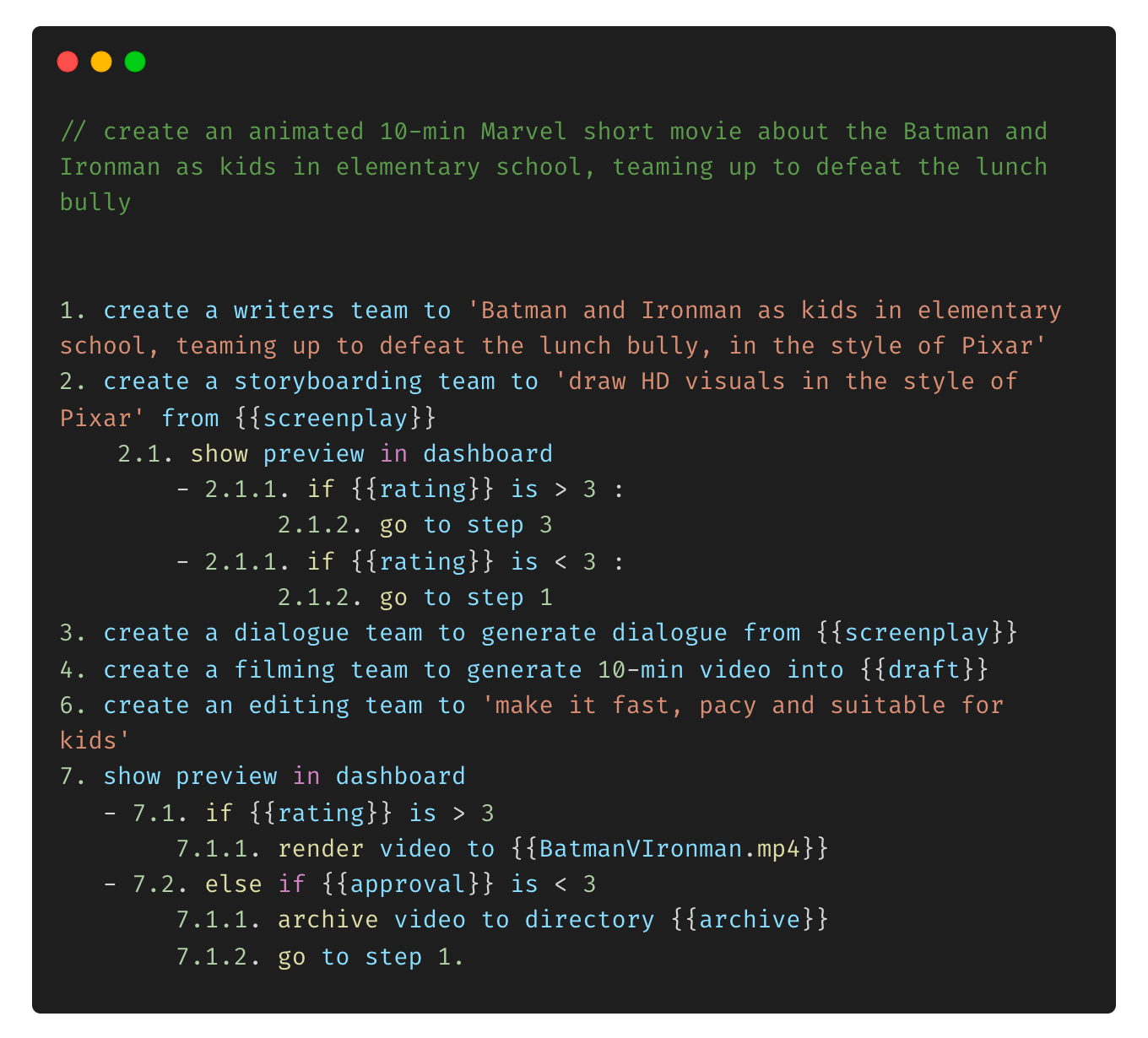
Each step in the above could then expand to multiple other steps, and so forth, as instructions given at a high level could percolate to lower levels. The higher the level of abstraction, the more complex tasks future PACs could write programs to do. These generated software programs could be chained to other programs, and that self-assembling graph could traverse the space of all industrial processes (Fig 11).
It's exciting to imagine what happens when anyone with an idea can hire a fleet of machines which can program themselves to do any task. How much new music, art, writing, science and enterprise sees the light of day - every day?
There is a gilded age of ideas on the other side, of a kind we've never seen before.
Sign up on our waitlist, or considering joining our team.
Contributors :
Sibesh, Shubham, Dushyant, Alabhya, Navneeth
Thanks also to : Gautham, Nilay, Shreyansh, Abhimanyu
